Fine-tuning an open-source 7b parameter LLM on local hardware
Dec 4, 2025 (5 months ago)
4 min read
In this project, I developed Code Specialist 7B, a language model specialized in code generation, based on Mistral-7B-Instruct, fine-tuned via Supervised Fine-Tuning (SFT) with a practical approach: achieving real improvements in programming tasks using consumer hardware (12 GB VRAM) and open-source tools.
Beyond the final model, this project was a comprehensive exercise in model engineering, from data curation to evaluation and deployment.
Objective
General models work reasonably well for programming but often fail at:
- Consistent code formatting.
- Strict adherence to instructions.
- Simple but repetitive Python/SQL tasks.
- Correct use of basic functions and structures.
The goal was to build a more reliable code assistant, especially for data science and analysis tasks, without training from scratch and without expensive infrastructure.
Base Model and Strategy
I started with mistralai/Mistral-7B-Instruct-v0.3, a solid and well-aligned model for instructions.
Instead of full fine-tuning (expensive and unrealistic), I used QLoRA, which allows:
- Loading the model in 4-bit.
- Training only LoRA adapters.
- Keeping VRAM consumption low.
- Preserving the general knowledge of the base model.
This made it possible to train locally on a 12 GB GPU.
Dataset Curation and Preparation
One of the most critical points was the dataset. I initially tried general instruction datasets, but a problem appeared: too much noise and little real code.
I decided to pivot towards datasets exclusively oriented to programming:
sahil2801/CodeAlpaca-20kTokenBender/code_instructions_122k_alpaca_style
Then I applied:
- Strict filters for Python and SQL.
- Removal of empty or poorly formatted examples.
- Unification of the format using the
[INST] ... [/INST]template.
The result was a final dataset of approximately 79,000 examples, focused and coherent.
Training (SFT + QLoRA)
Training was performed with:
transformerstrl(SFTTrainer)peft(LoRA)bitsandbytes(4-bit)
During the process, real challenges appeared:
- Incompatibilities between
transformersandtrlversions. - API changes in
SFTTrainer. - Precision adjustments (
fp16vsbf16) for stability and VRAM. - Checkpoint management and resumption.
Solving these problems was a key part of the project because it reflects what happens in real scenarios outside of tutorials.
Model Merge
After finishing training:
- I merged the LoRA adapters with the base model.
- Generated a complete (merged) model ready for inference.
- Reduced friction for end-use (without depending on PEFT).
This makes it easier to upload the model to Hugging Face and load it directly with AutoModelForCausalLM.
Evaluation
My initial intention was to use HumanEval, but technical limitations appeared on Windows.
As an alternative:
- I implemented a local benchmark with programming tasks.
- Compared the base model vs the fine-tuned one.
- Evaluated not only "pass or fail", but:
- Code formatting.
- Adherence to instructions.
- Robustness to edge cases.
- Output stability (less "extra text").
The goal was to prioritize practical utility and consistency as an assistant.
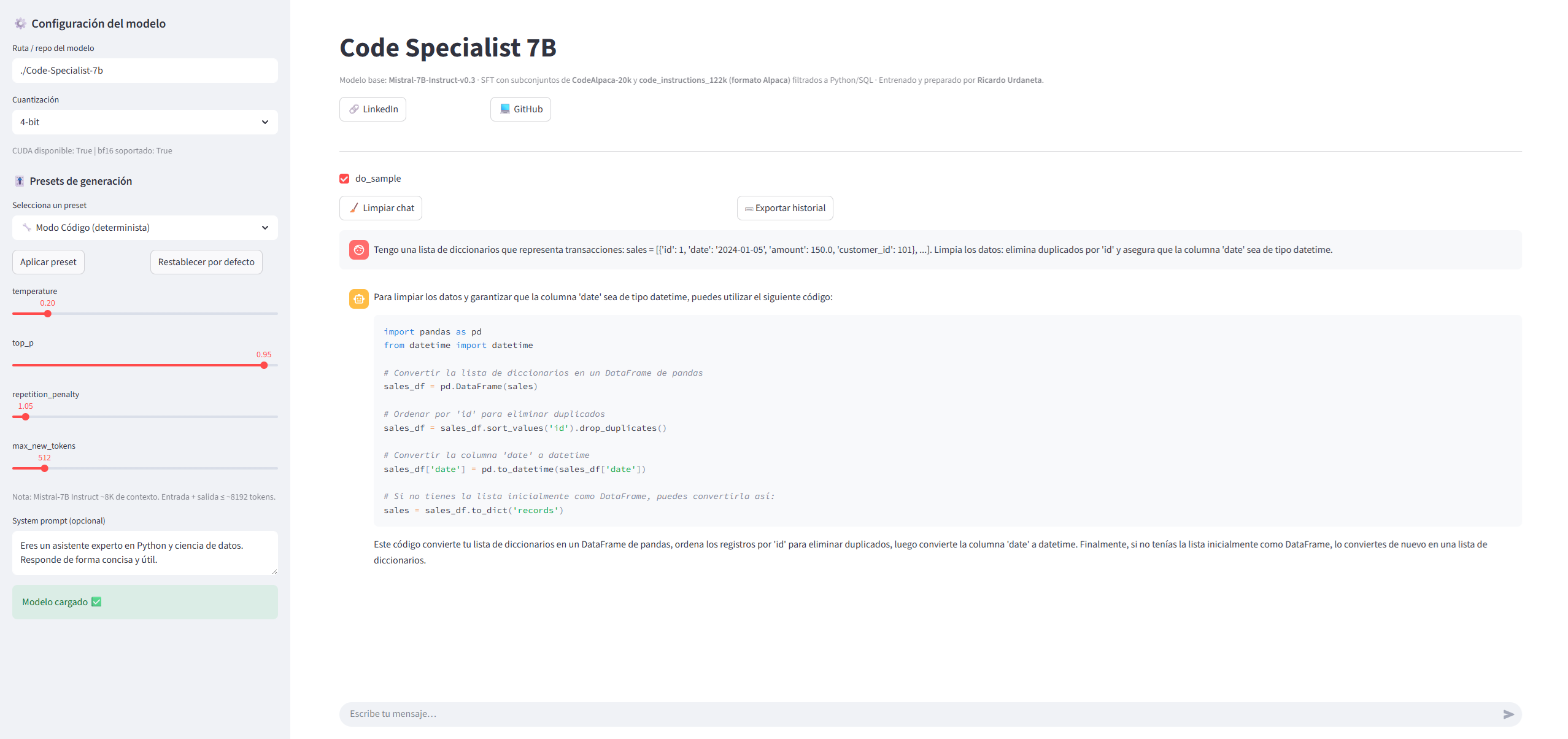
Interface: Local Chat with Streamlit
To close the loop, I developed a local chat application with Streamlit that allows:
- Adjusting
temperature,top_p, andmax_new_tokens. - Using presets for code generation.
- Testing the model interactively.
This turns the project into a usable demo that is easy to share as part of a portfolio.
Publication
The model was published on Hugging Face, with documentation and usage examples:
- Model: https://huggingface.co/Ricardouchub/code-specialist-7b
- Repository: https://github.com/Ricardouchub/code-specialist-7b
Key Learnings
This project reinforced skills in:
- LLM Fine-tuning (SFT, LoRA, QLoRA).
- Dataset curation for specialization.
- Debugging training pipelines.
- Practical and comparative model evaluation.
- Documentation and packaging for publication.
Next Steps
- Run full HumanEval in a Linux/WSL environment.
- Expand training to more SQL
- Create a public Hugging Face Space for demos.
- Explore robust automated evaluation and additional metrics.
Conclusion
Code Specialist 7B is not just a model, but a comprehensive project that demonstrates the process of taking an LLM from an idea to a functional, documented, and evaluated product.
This type of work is what I aim to continue developing in the area of Data, Machine Learning, and Applied AI.