Code Specialist 7B: afinando un LLM de código en hardware de consumo
4 dic 2025 (hace 5 meses)
4 min de lectura
En este proyecto desarrollé Code Specialist 7B, un modelo de lenguaje especializado en generación de código, basado en Mistral-7B-Instruct, afinado mediante Supervised Fine-Tuning (SFT) con un enfoque práctico: lograr mejoras reales en tareas de programación usando hardware de consumo (12 GB de VRAM) y herramientas open-source.
Más allá del modelo final, este proyecto fue un ejercicio completo de ingeniería de modelos, desde la curación de datos hasta la evaluación y despliegue.
Objetivo
Los modelos generales funcionan razonablemente bien para programación, pero suelen fallar en:
- Formato consistente de código.
- Cumplimiento estricto de instrucciones.
- Tareas simples pero repetitivas de Python/SQL.
- Uso correcto de funciones y estructuras básicas.
El objetivo fue construir un modelo más confiable como asistente de código, especialmente para tareas de ciencia y análisis de datos, sin entrenar desde cero y sin infraestructura costosa.
Modelo base y estrategia
Partí desde mistralai/Mistral-7B-Instruct-v0.3, un modelo sólido y bien alineado para instrucciones.
En lugar de un fine-tuning completo (costoso y poco realista), utilicé QLoRA, que permite:
- Cargar el modelo en 4-bit.
- Entrenar solo adaptadores LoRA.
- Mantener bajo el consumo de VRAM.
- Preservar el conocimiento general del modelo base.
Esto hizo posible entrenar localmente en una GPU de 12 GB.
Curación y preparación del dataset
Uno de los puntos más críticos fue el dataset. Inicialmente probé con datasets de instrucciones generales, pero apareció un problema: mucho ruido y poco código real.
Decidí pivotar hacia datasets exclusivamente orientados a programación:
sahil2801/CodeAlpaca-20kTokenBender/code_instructions_122k_alpaca_style
Luego apliqué:
- Filtros estrictos para Python y SQL.
- Eliminación de ejemplos vacíos o mal formateados.
- Unificación del formato usando la plantilla
[INST] ... [/INST].
El resultado fue un dataset final de aproximadamente 79 000 ejemplos, enfocado y coherente.
Entrenamiento (SFT + QLoRA)
El entrenamiento se realizó con:
transformerstrl(SFTTrainer)peft(LoRA)bitsandbytes(4-bit)
Durante el proceso aparecieron desafíos reales:
- Incompatibilidades entre versiones de
transformersytrl. - Cambios de API en
SFTTrainer. - Ajustes de precisión (
fp16vsbf16) para estabilidad y VRAM. - Manejo de checkpoints y reanudación.
Resolver estos problemas fue parte clave del proyecto, porque refleja lo que ocurre en escenarios reales fuera de tutoriales.
Merge del modelo
Tras finalizar el entrenamiento:
- Fusioné los adaptadores LoRA con el modelo base.
- Generé un modelo completo (merged) listo para inferencia.
- Reduje la fricción para uso final (sin depender de PEFT).
Esto facilita subir el modelo a Hugging Face y cargarlo directamente con AutoModelForCausalLM.
Evaluación
Mi intención inicial fue usar HumanEval, pero en Windows aparecieron limitaciones técnicas.
Como alternativa:
- Implementé un benchmark local con tareas de programación.
- Comparé el modelo base vs el afinado.
- Evalué no solo si “pasa o falla”, sino:
- Formato del código.
- Cumplimiento de instrucciones.
- Robustez ante edge cases.
- Estabilidad de la salida (menos “texto extra”).
El objetivo fue priorizar utilidad práctica y consistencia como asistente.
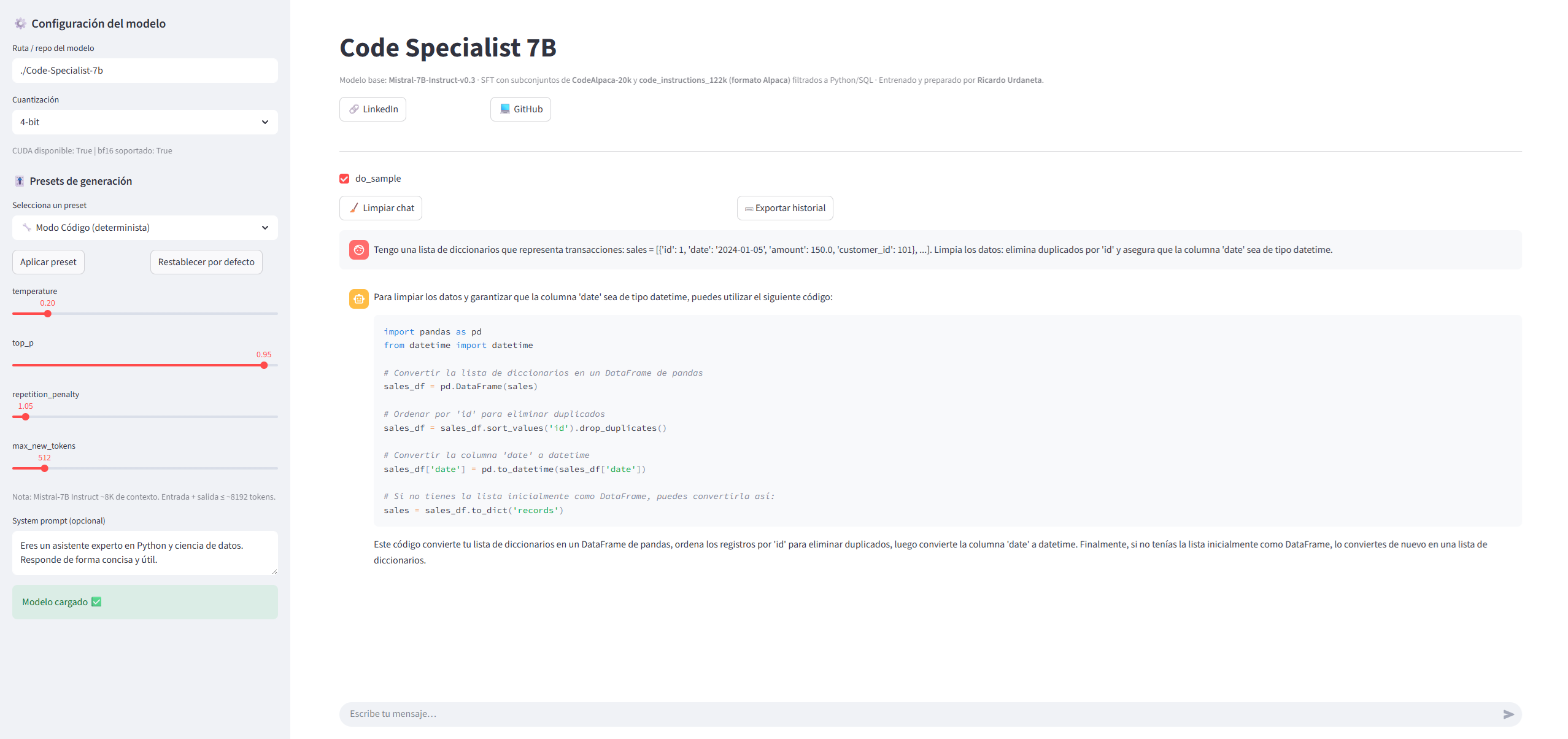
Interfaz: chat local con Streamlit
Para cerrar el ciclo, desarrollé una aplicación de chat local con Streamlit que permite:
- Ajustar
temperature,top_pymax_new_tokens. - Usar presets para generación de código.
- Probar el modelo de forma interactiva.
Esto convierte el proyecto en un demo usable y fácil de compartir como parte de un portfolio.
Publicación
El modelo fue publicado en Hugging Face, con documentación y ejemplos de uso:
- Modelo: https://huggingface.co/Ricardouchub/code-specialist-7b
- Repositorio: https://github.com/Ricardouchub/code-specialist-7b
Aprendizajes clave
Este proyecto reforzó habilidades en:
- Fine-tuning de LLMs (SFT, LoRA, QLoRA).
- Curación de datasets para especialización.
- Debugging de pipelines de entrenamiento.
- Evaluación práctica y comparativa de modelos.
- Documentación y empaquetado para publicación.
Próximos pasos
- Ejecutar HumanEval completo en entorno Linux/WSL.
- Expandir el entrenamiento a más tareas de SQL
- Crear un Hugging Face Space público para demos.
- Explorar evaluación automatizada más robusta y métricas adicionales.
Conclusión
Code Specialist 7B no es solo un modelo, sino un proyecto integral que demuestra el proceso de llevar un LLM desde una idea hasta un producto funcional, documentado y evaluado.
Este tipo de trabajo es el que busco seguir desarrollando en el área de Data, Machine Learning y AI aplicada.